
第6章 序列 字符串 列表 元组
本章主题
- 序列简介
- 字符串
- 列表
- 元组
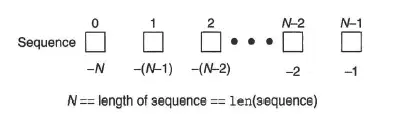
6.1 序列
访问模式:每一个元素可以通过制定一个偏移量的方式得到。而多个元素可以通过切片操作的方式一次得到。
6.11 标准类型操作符
标准类型操作符一般都能适用所有的序列类型。
6.1.2序列类型操作符
1.成员关系操作符(in、not in)
成员关系操作符用来判断一个元素是否属于一个序列的。
in、not in 操作符的返回值一般来讲就是True/False,满足成员关系就返回True,否则就是False
2.连接操作符(+)
此操作符允许我们把一个序列和另一个相同类型的序列做连接。语法:
sequence1+sequence2
3.重复操作符(*)
当你需要一个序列的多份拷贝的时候,重复操作符非常有用,语法如下:
sequence*copies_int
4.切片操作符 [] ,[:],[::]
>>> s=[0,1,2,3,4]
>>> s[:]
[0, 1, 2, 3, 4]
>>> s[0:3]
[0, 1, 2]
>>> s[:3]
[0, 1, 2]
>>> s[2:5]
[2, 3, 4]
>>> s[2:]
[2, 3, 4]
>>> s[1:3]
[1, 2]
>>> s[3]
3
>>> s[::]
[0, 1, 2, 3, 4]
5.用步长索引来扩展的切片操作
序列的最后一个切片操作的是扩展切片操作,它多出来的第三个索引值被用做步长数。
>>> s='abcdefgh'
>>> s[::-1] #可以视作“翻转”操作
'hgfedcba'
>>> s[::2] #隔一个取一个的操作
'aceg'
6.切片索引更多内容
切片索引的语法:开始和结束索引值可以超过字符串的长度。
>>> s=[1,2,3,4,5,6,7]
>>> s[-100:100]
[1, 2, 3, 4, 5, 6, 7]
每次把位于最后的一个字符砍掉。
>>> s='abcdefghijklmn'
>>> i=-1
>>> for i in range(-1,-len(s),-1):
print s[:i]
abcdefghijklm
abcdefghijkl
abcdefghijk
abcdefghij
abcdefghi
abcdefgh
abcdefg
abcdef
abcde
abcd
abc
ab
a
如何在第一次迭代的时候就显示整个字符串呢?
我们的方法:使用None作为索引值。
>>> s='abcdefghijklmn'
>>> for i in [None] + range(-1,-len(s),-1):
print s[:i]
abcdefghijklmn
abcdefghijklm
abcdefghijkl
abcdefghijk
abcdefghij
abcdefghi
abcdefgh
abcdefg
abcdef
abcde
abcd
abc
ab
a
我们假设另一种方法可以实现,给出代码如下:
>>> for i in [None].extend(range(-1,-len(s),-1)):
print s[:i]
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
for i in [None].extend(range(-1,-len(s),-1)):
TypeError: 'NoneType' object is not iterable
我们看见报错了。原因是:[None].extend(…)函数返回None,None既不是序列类型也不是可迭代的对象。
6.1.3 内建函数(BIF)
序列本身就内含了迭代的概念。迭代这个概念是从序列,迭代器,或其他支持迭代器操作的对象中泛化而来的。
python的for循环可以遍历所有的可迭代类型,在(非纯序列对象上)执行for循环时,就像在一个纯序列对象上执行一样。
1.类型转换
内建函数list()、str()、tuple()被用做在各种序列类型之间的转换。这种类型转换实际是工厂函数将对象作为参数将其内容拷贝到新生的对象中。
序列类型转换工厂函数
- list(iter) 可迭代对象转换列表
- str(obj) 把obj对象转换为字符串(对象的字符串表示方法)
- unicode(obj) 把对象转换为unicode字符串(使用默认编码)
- basestring() 抽象工厂函数,其作用仅仅是为str、unicode函数提供父类,所以不能被实例化也不能被调用
- tuple(iter) 把一个可迭代对象转换为一个元组对象
2.可操作
python为序列类型提供以下可操作的BIF。
注意:len()、reversed()、sum()函数只能接受序列类型对象作为参数,剩下的则还可以接受可迭代对象作为参数。
max()、min()函数也可以接受一个参数列表
序列类型可用的内建函数
- enumerate(iter) 接受一个可迭代的对象作为参数,返回一个enumerate 对象(同时也是一个迭代器),该对象生成由iter每个元素的index值和item值组成的元组
- len(seq) 返回seq的长度
- reverse(seq) 接受一个序列作为参数,返回一个逆序访问的迭代器
- sum(seq,init=0) 返回seq和可选参数init的总和,其效果等同于reduce(operator.add,seq,init)
- zip([it0,it1…itN]) 返回一个列表,其中第一个元素是it(),it1….这些元素组成的第一个元素组成的列表。
- sorted(iter,func) 接受一个可迭代的对象作为参数,返回一个有序的列表
6.2 字符串
通过在引号间包含字符的方式创建它。
python里面单引号和双引号的作用是相同的。
1.字符串的创建和赋值
创建一个字符串就像使用一个标量一样简单,可以吧str()作为工厂方法来创建一个字符串并把它赋值给一个变量
>>> aString='Hello world!' #使用单引号
>>> anotherString="Python is cool!" #使用双引号
>>> print aString
Hello world!
>>> anotherString
'Python is cool!'
>>> s=str(range(4))
>>> s
'[0, 1, 2, 3]'
2.如何访问字符串的值(字符和子串)
用方括号加一个或者多于一个索引的方式来获得子串:
>>> aString='Hello world!'
>>> aString[0]
'H'
>>> aString[1:5]
'ello'
>>> aString[6:]
'world!'
3.如何改变字符串
通过给一个变量赋值(或者重赋值)的方式“更新”一个已有的字符串。
>>> aString=aString[:6]+'Python!'
>>> aString
'Hello Python!'
>>> aString='different string altogether'
>>> aString
'different string altogether'
4.如何删除字符和字符串
字符串是不可变得,你可以清空一个字符串,或把剔除了需要的部分
>>> aString='Hello World!'
>>> aString=aString[:3]+aString[4:]
>>> aString
'Helo World!'
通过赋一个空字符串或使用del语句来清空或删除一个字符串:
>>> del aString
>>> aString
6.3 字符串和操作符
6.3.1 标准类的操作符
下面给出一些操作符是怎么样用于字符串类型的:
>>> str1='abc'
>>> str2='lmn'
>>> str3='xyz'
>>> str1<str2
True
>>> str2!=str3
True
>>> str1<str3 and str2=='xyz'
False
6.3.2 序列操作符切片([]和[:])
(1)正向索引
x是[start:end]中的一个索引值,那么 start<=x<end
>>> aString='abcd'
>>> len(aString)
4
>>> aString[0]
'a'
>>> aString[1:3]
'bc'
>>> aString[2:4]
'cd'
>>> aString[4]
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
aString[4]
IndexError: string index out of range使用不在本例范围内的索引值都会报错。
(2)反向索引
反向索引时候,从-1开始,向字符串的开始方位计数,到字符串长度的负数为索引的结束。
>>> aString='abcd'
>>> -len(aString)
-4
>>> aString[-1]
'd'
>>> aString[-3:-1]
'bc'
>>> aString[-4]
'a'
若开始索引或结束索引没有被指定,则分别以字符串的第一个和最后一个索引值为默认值。
>>> aString[2:]
'cd'
>>> aString[1:]
'bcd'
>>> aString[:-1]
'abc'
>>> aString[:]
'abcd'
(3)成员操作符(in, not in)
成员操作符用于判断一个字符串或者一个子串是否出现在另一个字符串中。出现为True,否则为False
>>> 'bc' in 'abcd'
True
>>> 'n' in 'abcd'
False
>>> 'nm' not in 'abcd'
True
例6-1 标识符检查(idcheck.py)
#!usr/bin/env python
import string
alphas=string.letters+'_'
nums=string.digits
print 'Welcome to the Identifier Checker v1.0'
print 'Testees must be at least 2 chars long.'
myInput=raw_input('Identifier to test')
if len(myInput)>1:
if myInput[0] not in alphas
print '''invalid:first symbol must be alphas'''
else:
for otherChar in myInput[1:]:
if otherChar not in myInput[1:]:
print '''invalid:remaining symbols must be alphanumberic'''
break
else:
print "okay as an identifier"
2. 连接符(+)
运行时刻字符串连接。通过连接操作符来从原有的字符串获得一个新的字符串。
>>> 'asndgfya'+'iwue9wqu'
'asndgfyaiwue9wqu'
>>> 'hello'+''+'world'
'helloworld'
>>> 'hello'+' '+'world'
'hello world'
>>> s='Spanish'+' '+'Inqusition'+' '+'Made Easy'
>>> s
'Spanish Inqusition Made Easy'
>>> import string
>>> string.upper(s[:3]+s[20])
'SPAA'
上面的例子(使用string模块)其实我们不建议使用。
我们可以用join()方法来把他们连接在一起:
>>> '%s %s' %('Spanish','Inquistion')
'Spanish Inquistion'
>>> s=' '.join(('Spanish','Inqusition','Made Easy'))
>>> s
'Spanish Inqusition Made Easy'
>>> ('%s%s' %(s[:3],s[20])).upper()
'SPAA'
3.编译时字符串连接
>>> foo="Hello" 'world!'
>>> foo
'Helloworld!'
4.普通字符串转化为unicode字符串
若把一个普通的字符串和一个Unicode字符串做连接处理,python会在连接操作前把普通字符串转化为unicode字符串:
>>> 'Hello'+u' '+'World'+u'!'
u'Hello World!'
>>> 'N!'*3
'N!N!N!'
6.4 只适用于字符串的操作符
6.4.1 格式化字符串(%)
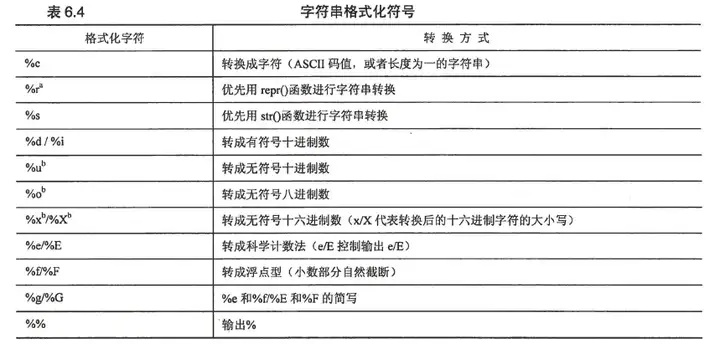
python支持两种格式的输入参数,第一种是元组,第二种是字典。
下面是一些使用格式字符串的例子:
1.十六进制
>>> "%x"% 108
'6c'
>>> "%#x"% 108
'0x6c
2.浮点型和科学计数法形式输出
>>> '%f'% 1234.56789
'1234.567890'
>>> '%.2f'%1234.56789
'1234.57'
>>> '%E' %1234.56789
'1.234568E+03'
>>> '%g'% 1234.56789
'1234.57'
>>> "%e" %(1111111111111111)
'1.111111e+15'
3.整型和字符串输出
>>> "%+d" % 4
'+4'
>>> "we are at %d%%" % 100
'we are at 100%'
>>> "MM/DD/YY=%02d/%02d/%d"%(2,15,67)
'MM/DD/YY=02/15/67'
6.4.2 字符串模板:更简单的替代品
>>> from string import Template
>>> s=Template('There are ${howmany} ${lang} Quotation Symbols')
>>> print s.substitute(lang='Python',howmany=3)
There are 3 Python Quotation Symbols
>>> print s.substitute(lang='Python')
Traceback (most recent call last):
File "<pyshell#23>", line 1, in <module>
print s.substitute(lang='Python')
File "D:\py\lib\string.py", line 176, in substitute
return self.pattern.sub(convert, self.template)
File "D:\py\lib\string.py", line 166, in convert
val = mapping[named]
KeyError: 'howmany'
>>> print s.safe_substitute(lang='Python')
There are ${howmany} Python Quotation Symbols
6.4.3 原始字符串操作符(r/R)
正则表达式的创建定义了高级搜索匹配方式的字符串,通常由字符、分组、匹配信息、变量名和子夫雷等特殊符号构成。
>>> '\n'
'\n'
>>> print '\n'
>>> r'\n'
'\\n'
>>> print r'\n'
\n
6.4.4Unicode字符串操作符(u/U)
Unicode操作符必须出现在原始字符串操作符的前面
ur’Hello\nWorld!’
6.5内建函数
6.5.1 标准类型函数
cmp()
同比较操作符一样,内建的cmp()函数也根据字符串的ASCII码值进行比较。
>>> str1='abc'
>>> str2='lmn'
>>> str3='xyz'
>>> cmp(str1,str2)
-1
>>> cmp(str3,str1)
1
>>> cmp(str2,'lmn')
0
6.5.2序列类型函数
(1)len()函数返回字符串的字符数
>>> str1='abc'
>>> len(str1)
3
>>> len('Hello world!')
12
(2)max() and min()函数能返回最大或最小的字符
>>> max(str2)
'n'
>>> min(str2)
'l'
>>> min('ab12cd')
'1'
>>> max('ab12cd')
'd'
(3)enumerate()
>>> s='foobar'
>>> for i,t in enumerate(s):
print i,t
0 f
1 o
2 o
3 b
4 a
5 r
(4)zip()
>>> s,t='foa','obr'
>>> zip(s,t)
[('f', 'o'), ('o', 'b'), ('a', 'r')]
6.5.3字符串类型函数
(1)raw_input()
内建函数raw_input()函数使用给定的字符串提示用户输入并将这个输入返回。
>>> uer_name=raw_input("Enter your name: ")
Enter your name: Tom
>>> uer_name
'Tom'
>>> len(uer_name)
3
(2)str() and unicode()
str() and unicode()都是工厂函数,就是说产生对应的类型的对象。接受一个任意类型的对象,然后创建该对象的可打印的或者unicode的字符串表示。
(3)chr() unichr() ord()
chr()函数返回一个对应的字符。unichr()返回的是unicode字符。
ord()函数是chr()函数或unichr()函数的配对
>>> chr(65)
'A'
>>> ord('a')
97
>>> ord(u'\2345')
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
ord(u'\2345')
TypeError: ord() expected a character, but string of length 2 found
>>> unichr(12345)
u'\u3039'6.6 字符串内建函数
书上给出了很多很全。我摘录几个常用的。
string.join(seq) 以string作为分隔符,将seq中所有的元素合并为一个新的字符串。
string.lower() 转换string中所有大写字符为小写
string.lstrip() 截掉string左边的空格
string.split(str=””,num=string.count(str))
以str为分隔符切片str,若num有指定值,则仅分隔num个子字符串
string.upper() 转换string中的小写字母为大写
>>> quest='what is your favorite color?'
>>> quest.count('or')
2
>>> ':'.join(quest.split())
'what:is:your:favorite:color?'
>>> quest.upper()
'WHAT IS YOUR FAVORITE COLOR?'
6.7 字符串的独特特性
6.7.1 特殊字符串的控制和控制字符
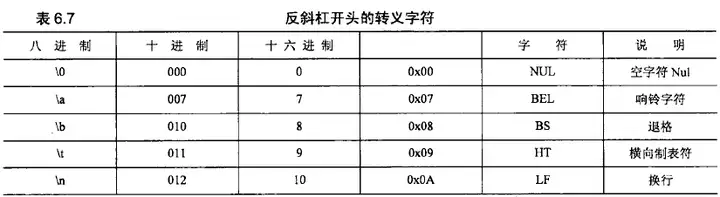
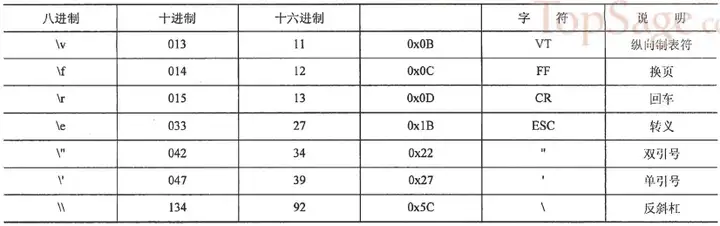
6.7.2 三引号
三引号允许字符串跨行多行。
6.73 字符串不变性
字符串是一种不可变得数据类型。
>>> 'abc'+'def'
'abcdef'
>>> s='abc'
>>> s=s+'abc'
>>> s
'abcabc'
6.8 Unicode
6.8.1术语
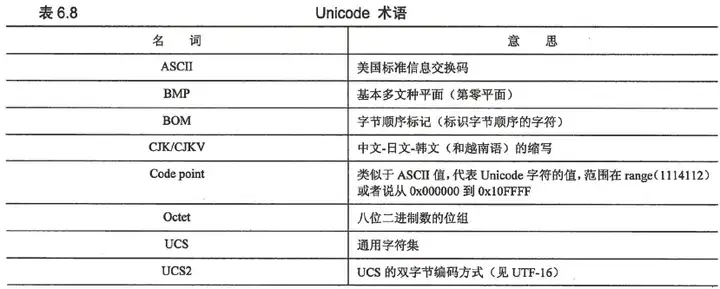
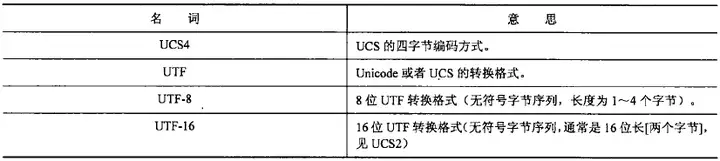
其中,较为熟悉的是,
ASCII 美国标准信息交换码
UTF-8 8位的转换格式(无符号字节序列,长度1-4个字节)
6.6.2 什么是Unicode
Unicode通过使用一个或多个字节来表示一个字符的方法突破例如ASII的限制。这种机制下,可以表示超过90000个字符。
6.8.3 怎么样用Unicode
新的内建函数unicode() 和 unichr() 可以看成是unicode版本的str()和 chr()
6.84 Codec 是什么
codec是COder/DECoder的首字母组合。定义了文本的二进制转换方式。
支持几种编码方式,如:UTF-8 ,ASCII
6.8.6 把unicode应用待实际应用中
遵守以下几个原则:
- 程序中出现字符串时一定要加个前缀u
- 不要用str()函数,用unicode()代替
- 不要使用过时的string模块
- 不到必须时不要在你的程序里面编解码Unicode字符。
6.8.8 python的unicode支持
1.RE引擎unicode的支持
正则表达式引擎需要Unicode支持。
utf-8 变量长度为8的编码
6.9 相关模块
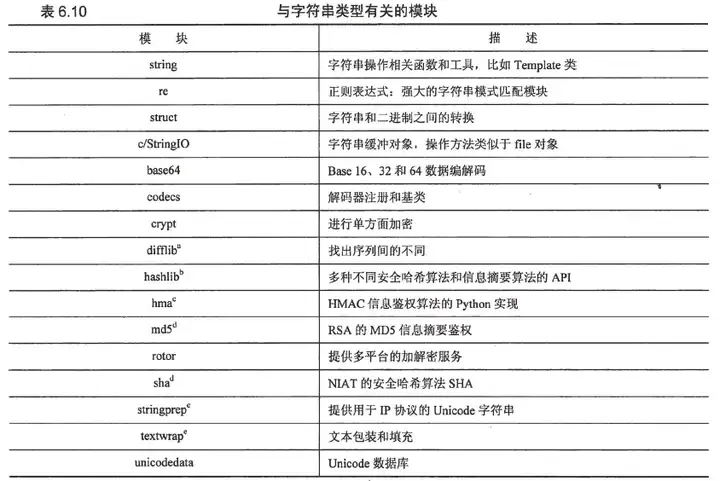
正则表达式(re),提供了高级的字符串模式匹配方案,通过描述这些模式的语法,可以像是要使用“过滤器”一样高效的查找传进来的文本。这些过滤器允许你基于自定义的模式字符串抽取匹配模式、执行查找-替换或分隔字符。
6.10 字符串关键点总结
1.一些引号分割的字符
2.不可分字符类型
3.字符串格式化字符(%)提供类似printf()功能
4.三引号
5.原始字符串对每个特殊字符串都使用它的原意
6. python字符串不是通过NULL或者’\0’来结束的
6.11 列表
1.如何创建列表数据类型并给它赋值
>>> alist=[123,'abc',4.56]
>>> print alist
[123, 'abc', 4.56]
2.访问列表中的值
列表的切片操作就像字符串中一样,切片操作符([])和索引值范围一起使用。
>>> alist=[123,'abc',4.56]
>>> print alist
[123, 'abc', 4.56]
>>> alist[0]
123
>>> alist[1:4]
['abc', 4.56]
>>> alist[:3]
[123, 'abc', 4.56]
>>> alist[:2]
[123, 'abc']
3.如何更新列表
>>> alist
[123, 'abc', 4.56]
>>> alist[2]
4.56
>>> alist[2]='replacer'
>>> alist
[123, 'abc', 'replacer']
4.如何删除列表中的元素或者列表本身
>>> alist
[123, 'abc', 'replacer']
>>> del alist[1]
>>> alist
[123, 'replacer']
6.12 操作符
6.12.1 标准类型操作符
>>> list1=['abc',123]
>>> list2=['xyz',789]
>>> list3=['abc',123]
>>> list1<list2
True
>>> list2<list3
False
>>> list2>list3 and list1==list3
True
6.12.2 序列操作符
1.切片([]和[:])
>>> num=[43,1.23,2,6.1e5]
>>> str_list=['jack','jumped','over']
>>> mix_list=[4,-1.9+6j,'beef']
>>> num[1]
1.23
>>> num[:2]
[43, 1.23]
>>> str_list[2]
'over'
>>> mix_list[1]
(-1.9+6j)
2.成员关系操作符
>>> 'x' in mix_list
False
>>> 4 in num
False
3.连接操作符
>>> num+mix_list
[43, 1.23, 2, 610000.0, 4, (-1.9+6j), 'beef']
>>> str_list+mix_list
['jack', 'jumped', 'over', 4, (-1.9+6j), 'beef']
4.重复操作符
>>> num*2
[43, 1.23, 2, 610000.0, 43, 1.23, 2, 610000.0]
>>> num*3
[43, 1.23, 2, 610000.0, 43, 1.23, 2, 610000.0, 43, 1.23, 2, 610000.0]
6.12.3列表类型操作符和列表解析
>>> [i*2 for i in [8,-2,5]]
[16, -4, 10]
>>> [i for i in range(8) if i%2==0]
[0, 2, 4, 6]
6.13 内建函数
6.13.1 标准类型函数
cmp()
>>> list1,list2=[123,'xyz'],[456,'abc']
>>> cmp(list1,list2)
-1
>>> cmp(list2,list1)
1
>>> list3=list2+[789]
>>> list3
[456, 'abc', 789]
>>> cmp(list2,list3)
-1
6.13.2 序列类型函数
1. len()
返回列表或元组的个数。
>>> num=[43,1.23,2,6.1e5]
>>> len(num)
4
2. max() 和min()
>>> str_list=['jack','jumped','over','candestick']
>>> max(num)
610000.0
>>> min(num)
1.23
>>> max(str_list)
'over'
>>> min(str_list)
'candestick'
3.sorted() reversed()
>>> s=['Thry','stamp','them','when',"they're",'small']
>>> for t in reversed(s):
print t
small
they're
when
them
stamp
Thry
>>> sorted(s)
['Thry', 'small', 'stamp', 'them', "they're", 'when']
4.enumerate() zip()
>>> for i,albums in enumerate(albums):
print i,albums
0 t
1 a
2 b
3 l
4 e
5 s
>>> fn=['ian','stuart','david']
>>> ln=['bairnson','elliott','paton']
>>>
>>> for i,j in zip(fn,ln):
print ('%s%s' %(i,j)).title()
Ianbairnson
Stuartelliott
Davidpaton
5.sum()
>>> a=[6,4,5]
>>> sum(a)
15
>>> sum(a,10)
25
6.list()和tuple()
list()函数和tuple()函数接受可迭代对象作为参数,并通过浅拷贝数据来创建一个新的列表或者元组。
6.14 列表类型内建函数
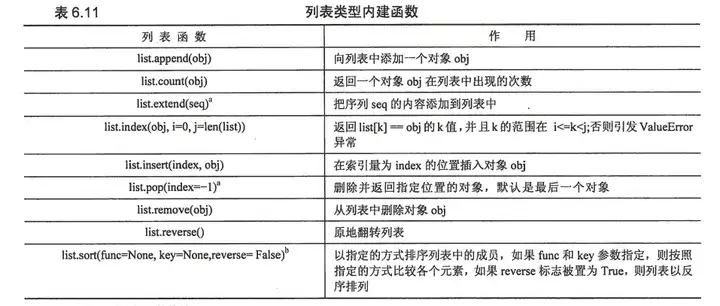
6.15 列表的特殊特性
1.堆栈
堆栈是一个后进先出(LIFO)的数据结构,想象放盘子的时候,第一个离开的堆栈的是你放上去的最后一个。
添加堆栈,使用“push”,删除一个元素,把它“pop”出堆栈。
2.队列
队列是一种 先进先出(FIFO)的数据结构,类似在超市排队时候,队列的第一个人先接受服务。
新的元素通过“入队”的方式进入队列末尾,“出队”就是从队列的头部删除。
6.16 元组
元组是跟列表一种非常相似的另一种容器类型。不同之处在于元组是用圆括号括起来的。
1.如何创建一个元组并赋值
>>> atuble=(123,'abc',4.56)
>>> print atuble
(123, 'abc', 4.56)
2.如何访问元组中的值
元组的切片与列表的切片一样。
>>> atuble[1:3]
('abc', 4.56)
>>> atuble[:3]
(123, 'abc', 4.56)
3.如何更新元组
元组是不可变类型。
>>> tup1=[12,34.56]
>>> tup2=['abc','xyz']
>>> tup3=tup1+tup2
>>> tup3
[12, 34.56, 'abc', 'xyz']
4.如何移除一个元组中的元素以及元组本身
删除一个单独的元组的元素是不可能的,多数时候是杀出一个对象。
del atuble
6.17 元组操作符和内建函数
6.17.1 标准类型操作符、序列类型操作符和内建函数
元组的对象和序列类型操作符和列表的完全一样,下面不做赘述。
1.创建、重复、连接操作
2.成员关系操作、切片操作
3.内建函数
4.操作符
6.18 元组的特殊特性
6.18.1不可变给元组带来了什么影响
数据类型是不可变的,一旦一个对象被定义了,值就不能再被更新,除非创造一个新的对象。
6.18.2 元组也不是那么“不可变”
元组本身是不可变的,但是元组包含的可变对象可以变
>>> t=(['xyz',123],23,-103.4)
>>> t
(['xyz', 123], 23, -103.4)
>>> t[0][1]
123
>>> t[0][1]=['abc','def']
>>> t
(['xyz', ['abc', 'def']], 23, -103.4)
6.18.3 默认集合类型
所有的多对象的、逗号分隔的、没有明确用符号定义的,这些集合默认的类型都是元组
所有函数返回的多对象都是元组类型。
6.18.4 单元素元组
无法创建一个元素的元组
>>> ('x')
'x'
>>> ('x',)
('x',)
>>> type ('x')
<type 'str'>
6.18.5 字典的关键字
不可变对象是不可变的,这也意味着通过hash算法得到的值总是一个值。
第7章 映像和集合类型
本章主题:
- 映射类型:字典
- 操作符
- 内建函数
- 内建方法
- 字典的键
- 集合类型
- 操作符
- 内建函数‘
- 内建方法
- 相关模块
7.1映射类型:字典
字典是python语言中唯一的映射类型,映射类型对象是哈希值(键,key)和指定的对象(值,value)是一对多的关系。
一个字典的对象是可变的,是一个容器类型,能储存任意个数的python对象,其中也包括其他容器类型。
字典类型和序列类型容器类(列表、元组)的区别是存储和访问的数据的方式不同。序列类型知识数字类型的键(从序列的开始起按数值顺序索引)。影响类型中的数据是无序排列的。
7.1.1 如何创建字典和给字典赋值
创建字典只需要给字典赋值一个变量,不管这个字典是否包含元素
>>> dict1={}
>>> dict2={'name':'earth','port':80}
>>> dict1,dict2
({}, {'name': 'earth', 'port': 80})
可以用工厂方法dict()创建字典
>>> fdict=dict((['x',1],['y',2]))
>>> fdict
{'y': 2, 'x': 1}
用一个内建方法fromkeys()来创建一个”默认“字典。字典中华元素具有相同的值
>>> ddict={}.fromkeys
>>> ddict={}.fromkeys(('x','y'),-1)
>>> ddict
{'y': -1, 'x': -1}
>>> edict={}.fromkeys(('foo','bar'))
>>> ddict
{'y': -1, 'x': -1}
7.1.2 如何访问字典中的值
要遍历一个字典(一般用键),只需要循环查看它的键。
>>> dict2={'name':'earth','port':80}
>>> for key in dict2.keys():
print 'key=%s,value=%s' %(key,dict2[key])
key=name,value=earth
key=port,value=80
你还可以使用迭代器来轻松地访问数据类型对象(sequence-like objects),比如字典和文件。只需要用字典的名字就可以在for循环里遍历字典。
>>> dict2={'name':'earth','port':80}
>>> for key in dict2:
print 'key=%s,value=%s' %(key,dict2[key])
key=name,value=earth
key=port,value=80
要得到字典中某个元素的值,可以使用你所熟悉的字典加上括号来得到。
>>> dict2['name']
'earth'
一个字典中混用数字和字符串的例子:
>>> dict3={}
>>> dict3[1]='abc'
>>> dict3['1']=3.14159
>>> dict3[3.2]='xyz'
>>> dict3
{'1': 3.14159, 1: 'abc', 3.2: 'xyz'}
除了逐一赋值之外,我们还可以给dict3整体赋值:
>>> dict3={'1': 3.14159, 1: 'abc', 3.2: 'xyz'}
>>> dict3
{'1': 3.14159, 1: 'abc', 3.2: 'xyz'}
7.1.3 如何更新字典
可以通过以下几种方式对字典进行修改:添加一个新数据项或新元素(一个键-值对):修改一个已经存在的数据项:或删除一个已经存在的数据项。
>>> dict2['name']='venus'
>>> dict2['port']=6969
>>> dict2['arch']='sunos5'
>>> dict2
{'arch': 'sunos5', 'name': 'venus', 'port': 6969}
7.1.4 如何删除字典元素和字典
删除整个字典,使用del语句。一般是删除单个元素或清除整个字典的内容。
del dict2[‘name’] #删除键为‘name’的条目
dict2.clear() #删除dict 中所有条目
del dict2 #删除整个dict字典
dict2.pop(‘name’) #删除并返回键值为‘w’的条目
7.2 映射类型操作符
字典可以和所有的标准类型操作符一起工作。但是不支持像拼接和重复这样的操作
7.2.1 标准类型操作符
下面进行操作符的简单示例
>>> dict4={'abc':123}
>>> dict5={'abc':456}
>>> dict6={'abc':123,97.3:83}
>>> dict7={'xyz':123}
>>> dict4<dict5
True
>>> dict4
{'abc': 123}
>>> (dict4<dict6) and (dict4<dict7)
True
>>> (dict5<dict6) and (dict5<dict7)
True
>>> dict6<dict7
False
7.2.2 映射类型操作符
1.字典的键查找操作符([])
键查找操作符是唯一用于字典类型的操作符,它和序列类型里的单一元素的切片(slice)操作符很像。
对于字典类型来说,用键查询(字典里的元素),键为参数,而非一个索引。键操作符可以给字典赋值,也可以用于从字典中取值:
d[k]v 通过键’k’,给字典中某元素赋值’v’
d[k] 通过键’k’,查询字典中元素的值
2.(键)成员关系操作(in、not in)
用 in 和 not in 来检查某个键是否在字典中
>>> 'abc' in dict4
True
>>> 'name' in dict4
False
7.3 映射型的内建函数和工厂函数
7.3.1 映射类型相关的函数
如果参数是可以迭代的,一个支持迭代的对象,那么每个迭代的元素都必须成对的出现。
>>> dict(zip(('x','y'),(1,2)))
{'y': 2, 'x': 1}
>>> dict([['x',1],['y',2]])
{'y': 2, 'x': 1}
>>> dict(['xy'[i-1],i] for i in range(1,3))
{'y': 2, 'x': 1}
>>> dict8=dict(x=1,y=2)
>>> dict9=dict(**dict8)
>>> dict
<type 'dict'>
>>> dict9
{'y': 2, 'x': 1}
>>> dict9=dict8.copy
>>> dict9=dict8.copy()
>>> dict9
{'y': 2, 'x': 1}
内建函数len()函数,对字典调用它,会返回所有的元素(键-值对)的数目
>>> dict9
{'y': 2, 'x': 1}
>>> len (dict9)
2
内建函数hash(),可以判断某个对象是否可以作为一个字典的键。
对一个对象作为参数传递给hash(),会返回这个对象的哈希值。只有这个对象是哈希的,才可以作为字典的键(函数的返回值是整型,不产生错误或异常)
>>> hash([])
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'
如果非哈希类型的值传递给hash()方法,就会报错
下面我们给出3个映射类型的相关函数
dict([container]) 创建字典的工厂函数,提供了容器类(container),就用其中的条目填充字典,否则就创建一个空字典。
len(mapping) 返回映射的长度(键-值的个数)
hash(obj) 返回objde 的哈希值
7.4 映射类型的内建方法
基本的字典方法关注他们的键和值。
keys()方法,返回一个列表,包含字典中的所有键;
values()方法,返回一个列表,包含字典中的所有值;
items(),返回一个包含所有(键,值)元组的列表。
>>> dict9
{'y': 2, 'x': 1}
>>> dict9.keys()
['y', 'x']
>>> dict9.values()
[2, 1]
>>> dict9.items()
[('y', 2), ('x', 1)]
7.5 字典的键
字典的值是没有限制的,字典的键是有类型限制的。
7.5.1 不允许一个键对应多个值
原则:每个键只能对应一个项。当键发生冲突时,取最后(最近)的赋值
>>> dict10={'f':123,'f':'xyz'}
>>> dict10
{'f': 'xyz'}
>>> dict10['f']
'xyz'
键’f’所对应的值被替换了两次,最后的赋值语句,值123代替了值’xyz’
7.5.2 键必须是可哈希的
多数python对象可以作为键,但他们必须是可哈希的。
像列表和字典这样的可变类型,不可哈希,不可作为键。
本章小结 一个程序:管理用户名和密码的模拟登陆数据系统
#!/usr/bin/env/python
db=() #空数据库初始化程序
def newuser():
prompt='login desired:'
while Ture:
name=raw_input(prompt)
if db.has_key(name):
prompt='name taken,try another:'
continue
else:
break
pwd=raw_input('passwd:')
db[name]=pwd
def olduser():
name=raw_input('login:')
pwd=raw_input('passwd:')
passwd=bd.get(name)
if passwd==pwd:
print 'welcome back',name
else:
print 'login incorrect'
def showmenu():
prompt=
7.6 集合类型
数学上,把set称作不同的元素组成的集合,集合(set)的成员通常被称作元素
集合对象是一组无序排列的哈希值。
7.6.1 如何创建集合类型和集合赋值
用集合工厂的方法set()和frozenset()
>>> s=set('cheeseshop')
>>> s
set(['c', 'e', 'h', 'o', 'p', 's'])
>>> t=frozenset('bookshop')
>>> t
frozenset(['b', 'h', 'k', 'o', 'p', 's'])
>>> type(s)
<type 'set'>
>>> type(t)
<type 'frozenset'>
>>> len(s)
6
>>> len(s)==len(t)
True
>>> s==t
False
7.6.2 如何访问集合中的值
可以遍历看集合成员或检查某项元素是否是一个集合的成员
>>> 'k' in s
False
>>> 'k' in t
True
>>> 'c' not in s
False
>>> for i in s:
print i
c
e
h
o
p
s
7.6.3 如何更新集合
用集合内建的方法和操作符来添加和删除集合成员
>>> s.add('z')
>>> s
set(['c', 'e', 'h', 'o', 'p', 's', 'z'])
>>> s.update('pypi')
>>> s
set(['c', 'e', 'i', 'h', 'o', 'p', 's', 'y', 'z'])
>>> s.remove('z')
>>> s
set(['c', 'e', 'i', 'h', 'o', 'p', 's', 'y'])
>>> s-=set('pypi')
>>> s
set(['c', 'e', 'h', 'o', 's'])
只有可变集合能被改变,不可变集合更改的时候就会报错
>>> t.add('z')
Traceback (most recent call last):
File "<pyshell#73>", line 1, in <module>
t.add('z')
AttributeError: 'frozenset' object has no attribute 'add'
7.6.4 如何删除集合中的成员和集合
调用del即可
>>> del s
>>> s
Traceback (most recent call last):
File "<pyshell#75>", line 1, in <module>
s
NameError: name 's' is not defined
7.7 集合类型操作符
7.7.1 标准类型操作符(所有的集合类型)
1.成员关系(in,not in)
略
2.集合等价/不等价
>>> s=set('cheeseshop')
>>> s
set(['c', 'e', 'h', 'o', 'p', 's'])
>>> s==t
False
>>> s!=t
True
>>> u=frozenset(s)
>>> s==u
True
>>> set('posh')==set('shop')
True
3.子集/超集
小于符号(<或<=)用来判断子集
大于负荷(>或>=)用来判断超集
>>> set('shop')<set('cheeseshop')
True
>>> set('bookshop')>=set('shop')
True
7.7.2 集合类型操作符(所有的集合类型)
1.联合(|)
联合操作和集合的OR操作是等价的。
>>> s|t
set(['c', 'b', 'e', 'h', 'k', 'o', 'p', 's'])
2.交集(&)
交集集合和集合的AND操作是等价的,相同元素将合并
>>> s&t
set(['h', 's', 'o', 'p'])
3.差补/相对补集
两个几个的差补/相对补集指一个集合C,只属于集合s,不属于t
>>> s-t
set(['c', 'e'])
4.对差等分
和他的布尔集合操作类似,对称差分是集合的XOR(又称之为异或)
>>> s^t
set(['b', 'e', 'k', 'c'])
>>> t|s
frozenset(['c', 'b', 'e', 'h', 'k', 'o', 'p', 's'])
>>> t^s
frozenset(['c', 'b', 'e', 'k'])
>>> t-s
frozenset(['k', 'b'])
7.8 内建函数
7.8.1标准内建函数
len()
把集合作为参数传递给len()函数,返回集合的基数
>>> s=set(u)
>>> s
set(['p', 'c', 'e', 'h', 's', 'o'])
>>> len(s)
6
7.8.2 集合类型工厂函数
set() frozenset()
set() frozenset()工厂函数分别用来生成可变和不可变集合。
>>> set()
set([])
>>> set([])
set([])
>>> set(())
set([])
>>> set('shop')
set(['h', 's', 'o', 'p'])
>>> frozenset(['foo','bar'])
frozenset(['foo', 'bar'])
>>> f=open('number','w')
>>> for i in range(5):
f.write('%d\n' % i)
>>> f.close()
>>> f=open('number','r')
>>> set(f)
set(['0\n', '3\n', '1\n', '4\n', '2\n'])
>>> f.close()
7.9 集合类型内建方法
7.9.1 方法(所有的集合方法)
s.copy() 返回一个新集合,它是集合s的浅复制
7.9.2 方法(仅仅只用于可变集合)
- s.update(t) 用t中的元素修改s,s现在包含s或t的成员
- s.add(obj) 在集合s中添加对象obj
- s.remove(obj) 从集合对象中删除对象obj
- s.discard(obj) 如果obj是集合s中的元素,从集合s中删除对象obj
- s.pop() 删除集合s中的任意一个对象,并返回它
- s.clear() 删除集合s中所有对象
声明:
以上学习笔记来自
《python核心编程》第2版 Wesley J.Chun 编著 宋吉广译 人民邮电出版社


发表评论